With skills now front and center in every company’s talent initiatives, our resident AI expert Rabih Zbib decided to offer some valuable insights into how machine learning and AI can offer valuable aid in the form of skills semantics.
Rabih currently works at Avature as Director of Natural Language Processing & Machine Learning. He holds a PhD and a Masters in Science from MIT and is constantly working on improving talent strategies through the AI lens.
The world of talent management is going through a tectonic change, one in which skills play a central role in how HR teams acquire and manage their talent. As this process has accelerated, the need for automatic extraction and measurement of skills when sourcing candidates has also increased significantly. So much so that skills have been dubbed the “new currency of talent”.
While we have already described Avature’s approach to skills management and AI’s role in a previous article, in this one, we will focus on one of its key aspects: skills semantics. In other words, understanding the meaning of skills.
Why Are Skills Semantics Important?
If skills are used as an indicator for specific knowledge or expertise needed to achieve an outcome, then assessing the fitness of a candidate to a job position requires an understanding of the meaning of the candidate’s skills and those required by the job position. At the risk of getting too philosophical, we need to look at what we mean by ‘meaning’ in this context.
Generally, the meaning of a word could be thought of as the set of objects or concepts in the real world that the word refers to. For example, the meaning of chair is all the chairs out there, both the physical and the conceptual ones. This definition is referred to as referential semantics in linguistics. Another view, taken by distributional semantics, is that a word (or term) can be determined through its distribution, that is to say, from the contexts in which it frequently occurs. This assumption is referred to as the “distributional hypothesis”.
”You shall know a word by the company it keeps.“
John Rupert Firth
Linguist
This is a useful definition for the case of skills semantics since what we need is to be able to compare skills and to decide the relevance of one skill to another. But matching the exact name of the skills is clearly not enough here because they can be referred to by other names (programming vs. software development). Also, the presence of a certain skill can indicate the implicit presence of another. For example, suppose you’re interested in candidates with programming skills. In that case, someone with Java, C++ or Python experience is obviously a skilled programmer, even if the skill ‘programming’ is not spelled out explicitly on their profile.
The Role of AI
So there is a need to determine how skills relate to each other, in order to use them effectively for talent management. In other words, we need skills semantics. However, we do not want to build this information through manual knowledge engineering. This approach has many disadvantages. For starters, it requires detailed expertise in multiple industries and sectors. Also, it is brittle and cannot be easily extended. Since new skills are emerging all the time, and since the meaning of skills and their relations drift over time, an automated method is needed to learn the skills semantics.
This is where AI plays an important role. We can automatically learn the meaning of skills from real data, using machine learning models. This process is repeatable (scalable) with new skills and new data, and it also does not require deep subject-matter expertise in so many different domains.
Skill Embeddings
So how do we learn the meaning of skills using distributional semantics? We use a popular technique from natural language processing called “word embeddings”. This technique, also referred to as word2vec, represents each word as a point (or vector embedding) in a space of high dimensions (e.g., 100).
The algorithm that maps each word to its corresponding point in the embedding space relies on the distributional hypothesis that we mentioned above (namely that words that occur in the same context have related meaning). More concretely, a neural network is trained to predict the position of the embedding of each word based on the context words for that point.
We adapt word embeddings to represent skills, where each skill corresponds to a single point in the embedding space, even when the skill contains more than one word (e.g., application-specific integrated circuits). In that sense, each point in the embedding space represents a concept rather than a word. We estimate the skill2vec embeddings similar to how word2vec embeddings are estimated: by training a Deep Neural Network (DNN) model on skills data.
We start by collecting sets of related skills from anonymized resumes and job descriptions. For example, we might extract the following job:
- Job Title: Analog Design Engineer
- Skills: design, testing, circuit design, Verilog, phase-locked loop, …
We train the DNN by hiding a skill (say circuit design) and force the model to predict it from the other “context” skills: design, testing, Verilog, phase-locked loop, …
The DNN will initially make errors in prediction, but the training process updates the parameters of the DNN to reduce those errors, using the standard backpropagation algorithm. This process is repeated over many iterations, using millions of data samples (our typical setup uses about 45 million job records), until the DNN parameters converge to a set of values that reduces the prediction errors sufficiently.
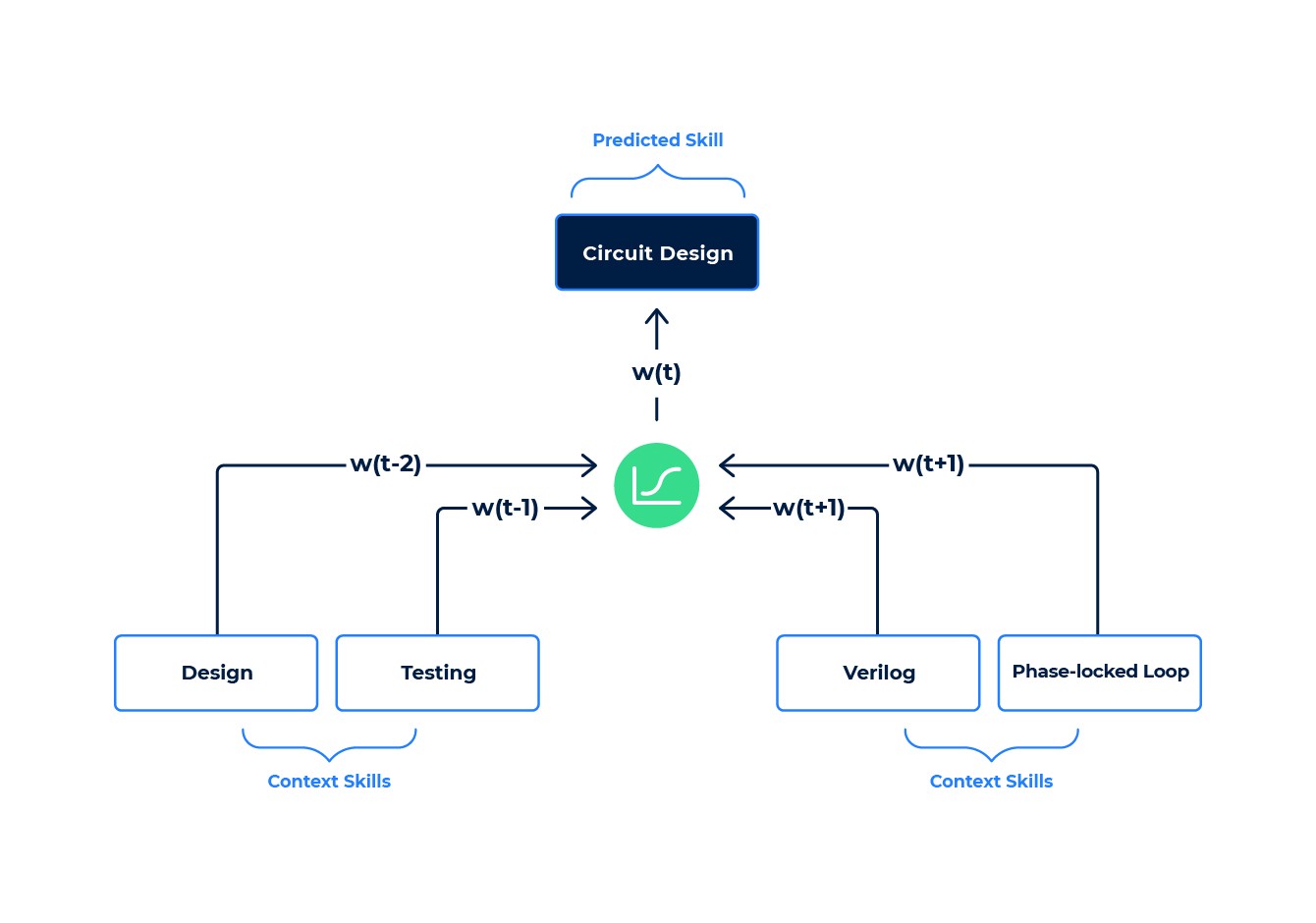
Skill embeddings training example.
The resulting DNN can now map each skill to a single point in the embeddings space. But this mapping has an important property: Skills that occur in a similar context —and therefore have a similar meaning— will end up close together in the embedding space. This is crucial because now we can measure the degree of similarity in the meaning of skills quantitatively by measuring the distance between their embeddings in the skill2vec space. For example, in our embeddings, we get SIMILARITY(software development, java): 0.7136, while SIMILARITY(software development, carpentry): 0.0706 is ten times lower.
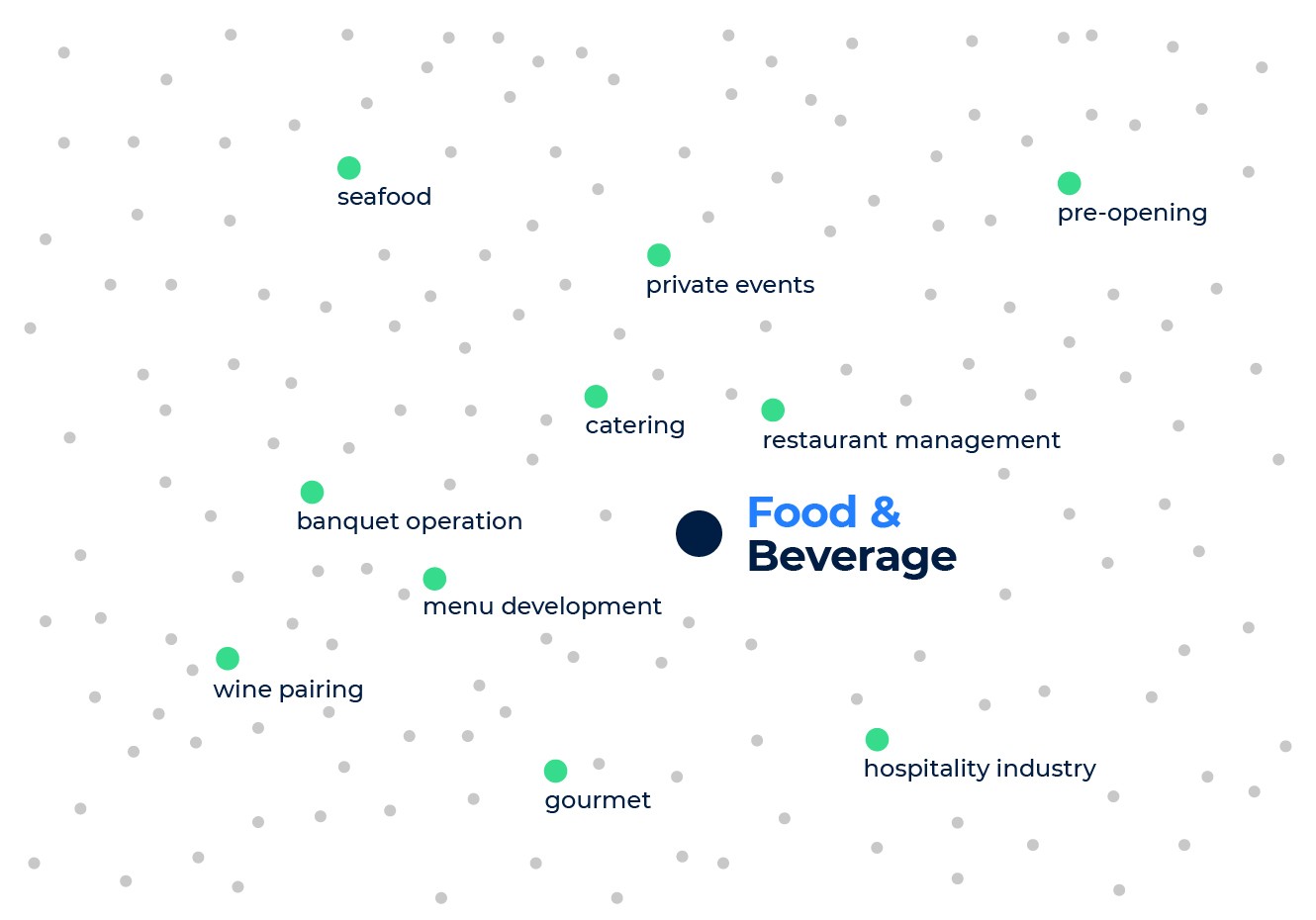
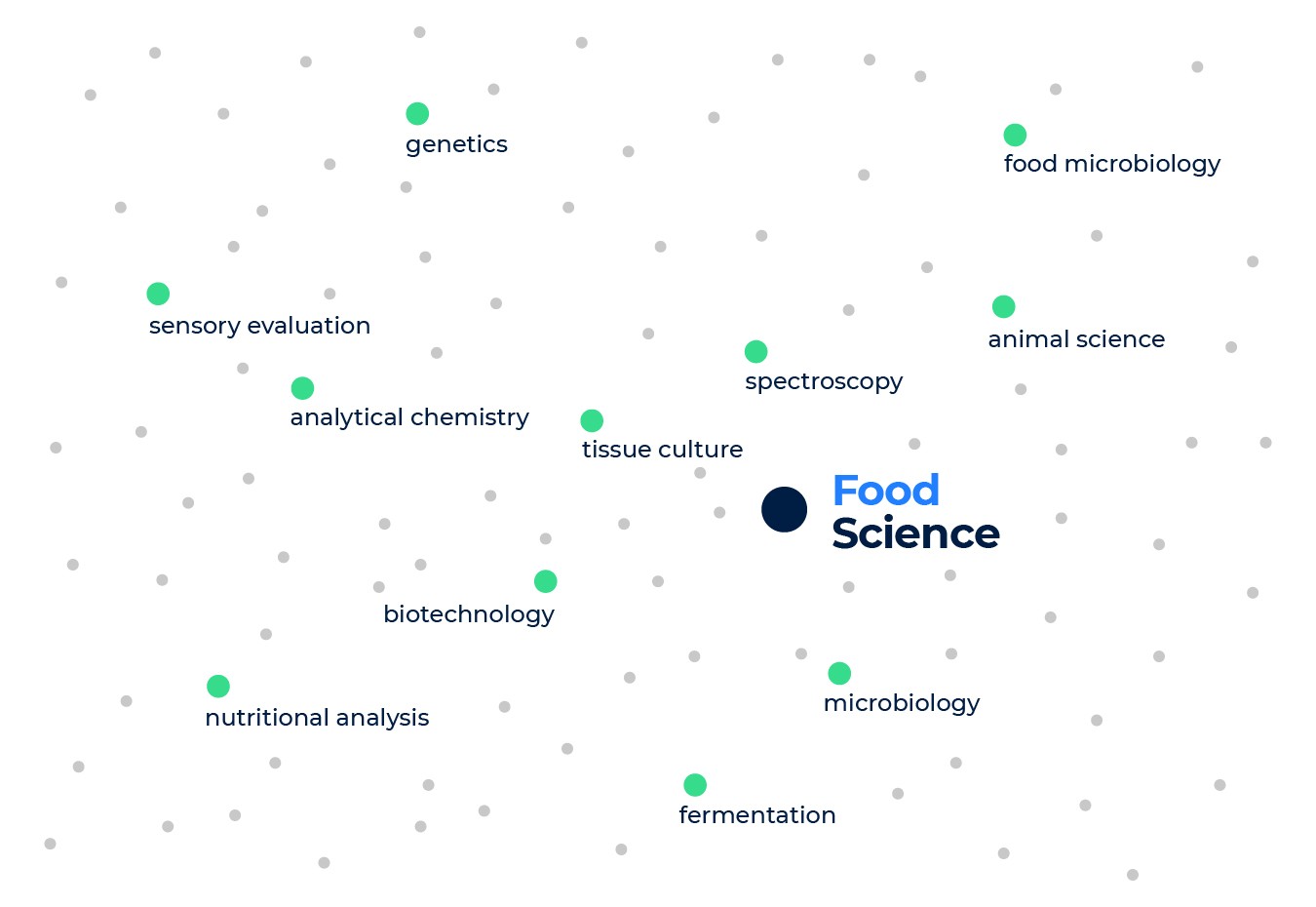
Let’s look at an example to illustrate the properties of the skill embeddings further. Consider the two skills: food and beverage, and food science. If we look at the skills with the closest embeddings to food and beverage, we find restaurant management, cooking, catering, menu development, etc. But when we look at the closest skills to food science we find molecular biology, analytical chemistry, polymerase chain reaction, and sensory evaluation.
We see that the two skills have very different neighbors because they are relevant to two different industries (the food services industry vs. the food development and manufacturing industry), and each implies a different set of skills. This is despite both skills sharing the word food, which shows how the skill embeddings capture the semantics of the skills and go beyond keywords.
Nearest neighbors to the skill “food and beverage”
Nearest neighbors to the skill “food science”
To Conclude…
The skill embeddings are a cornerstone for a lot of our AI-powered functionality. They are used to perform skill-based matching or to suggest related skills. In the next installment, we will describe how we use the skill embeddings to train a model for measuring the similarity between job titles.
If you enjoyed this inside look into how AI and machine learning work together and want to learn more, you can get in touch with us. You can also watch our interview with Fosway, where we go a bit more in-depth into our white-box approach to AI in Avature.


