Da Kompetenzen heute im Mittelpunkt der Talentinitiativen eines jeden Unternehmens stehen, hat sich unser KI-Experte Rabih Zbib entschlossen, einige wertvolle Einblicke in die Möglichkeiten zu geben, die maschinelles Lernen und KI in Bezug auf die Semantik von Kompetenzen bieten können.
Rabih Zbib arbeitet derzeit bei Avature als Director of Natural Language Processing & Machine Learning. Er hat einen PhD und einen Master in Naturwissenschaften vom MIT und arbeitet kontinuierlich an der Verbesserung von Talentstrategien durch die KI-Brille.
Die Welt des Talentmanagements befindet sich im Umbruch. Kompetenzen spielen heute eine zentrale Rolle dabei, wie HR-Teams ihre Talente akquirieren und verwalten. In dem Maße, wie sich dieser Prozess beschleunigt hat, ist auch der Bedarf an einer automatischen Extraktion und Messung von Kompetenzen beim Sourcing von Kandidaten deutlich gestiegen. So sehr, dass Kompetenzen als die „neue Währung der Talente“ bezeichnet werden.
Wir haben den Ansatz von Avature zum Kompetenzmanagement und die Rolle der KI bereits in einem früheren Artikel dargelegt. In diesem Artikel konzentrieren wir uns auf einen der wichtigsten Aspekte: die Semantik der Kompetenzen. Mit anderen Worten: Es geht darum, die Bedeutung von Kompetenzen zu verstehen.
Warum ist die Semantik von Kompetenzen wichtig?
Wenn Kompetenzen als Indikator für spezifisches Wissen oder Fachkenntnisse dienen, die zum Erreichen eines Ergebnisses erforderlich sind, dann verlangt die Beurteilung der Eignung eines Kandidaten für eine Stelle, dass man versteht, was die Kompetenzen des Kandidaten und die für die Stelle erforderlichen Kompetenzen bedeuten. Auf die Gefahr hin, zu philosophisch zu werden, müssen wir näher erläutern, was wir in diesem Zusammenhang unter ‚Bedeutung‘ verstehen.
Grundsätzlich kann man sich die Bedeutung eines Wortes als die Menge der Objekte oder Konzepte in der realen Welt vorstellen, auf die sich das Wort bezieht. Die Bedeutung des Wortes Stuhl umfasst beispielsweise alle Stühle in der Welt, sowohl die tatsächlich existierenden als auch die bloß gedachten. Diese Definition wird in der Linguistik als referentielle Semantik bezeichnet. Eine andere Sichtweise, die von der distributionellen Semantik vertreten wird, besagt, dass ein Wort (oder ein Begriff) durch seine Verbreitung bestimmt werden kann, d. h. durch die Kontexte, in denen es häufig vorkommt. Diese Annahme wird als „Verteilungshypothese“ bezeichnet.
„Du sollst ein Wort an der Gesellschaft erkennen, die es umgibt.“
John Rupert Firth
Linguist
Dies ist eine nützliche Definition für die Semantik von Kompetenzen, da wir in der Lage sein müssen, Kompetenzen zu vergleichen und die Relevanz einer Kompetenz für eine andere zu bestimmen. Die genaue Bezeichnung der Kompetenzen reicht hier jedoch nicht aus, da sie auch anders bezeichnet werden können (Programmierung vs. Softwareentwicklung). Außerdem kann das Vorhandensein einer bestimmten Kompetenz auf das implizite Vorhandensein einer anderen hinweisen. Nehmen wir zum Beispiel an, Sie sind an Kandidaten mit Programmierkompetenzen interessiert. Dann ist jemand mit Erfahrungen in Java, C++ oder Python eindeutig ein qualifizierter Programmierer, auch wenn die Kompetenz ‚Programmieren‘ nicht explizit in seinem Profil aufgeführt ist.
Die Rolle der KI
Wir müssen also bestimmen können, wie Kompetenzen zueinander in Beziehung stehen, um sie effektiv für das Talentmanagement zu nutzen. Mit anderen Worten: Wir brauchen eine Semantik der Kompetenzen. Wir wollen diese Informationen jedoch nicht durch manuelles Wissensmanagement aufbauen. Diese Vorgehensweise hat zahlreiche Nachteile. Zunächst einmal erfordert sie detaillierte Fachkenntnisse in mehreren Branchen und Sektoren. Außerdem ist sie fehleranfällig und lässt sich nur schwer erweitern. Da ständig neue Kompetenzen entstehen und sich die Bedeutung von Kompetenzen und deren Beziehungen im Laufe der Zeit verändern, ist eine automatisierte Methode erforderlich, um die Semantik der Kompetenzen zu erlernen.
Hier spielt die KI eine wichtige Rolle. Mithilfe von Machine-Learning-Modellen können wir die Bedeutung von Kompetenzen automatisch aus echten Daten lernen. Dieser Prozess ist mit neuen Kompetenzen und neuen Daten wiederholbar (skalierbar), und er erfordert kein umfangreiches Fachwissen in vielen verschiedenen Bereichen.
Kompetenzeinbettung
Wie können wir also die Bedeutung von Kompetenzen mithilfe der distributionellen Semantik erlernen? Wir verwenden eine beliebte Technik aus der natürlichen Sprachverarbeitung (NLP, Natural Language Processing), die sogenannte „Worteinbettung“. Diese Technik, die auch als word2vec bezeichnet wird, stellt jedes Wort als einen Punkt (oder eine Vektoreinbettung) in einem Raum mit hohen Dimensionen (z. B. 100) dar.
Der Algorithmus, der jedes Wort einem entsprechenden Punkt im Einbettungsraum zuordnet, beruht auf der oben erwähnten Verteilungshypothese (nämlich, dass Wörter, die im gleichen Kontext vorkommen, eine verwandte Bedeutung haben). Konkret wird ein neuronales Netzwerk trainiert, um die Position der Einbettung jedes Wortes auf der Grundlage der Kontextwörter für diesen Punkt vorherzusagen.
Wir adaptieren die Worteinbettung zur Darstellung von Kompetenzen, wobei jede Kompetenz einem einzigen Punkt im Einbettungsraum entspricht, selbst wenn die Kompetenz mehr als ein Wort enthält (z. B. anwendungsspezifische integrierte Schaltkreise). In diesem Sinne stellt jeder Punkt im Einbettungsraum eher ein Konzept als ein Wort dar. Wir ermitteln die skill2vec-Einbettungen ähnlich wie die word2vec-Einbettungen: durch das Trainieren eines DNN-Modells (Deep Neural Network) anhand der Kompetenzdaten.
Wir beginnen damit, dass wir eine Reihe verwandter Kompetenzen aus anonymisierten Lebensläufen und Stellenbeschreibungen sammeln. Wir könnten zum Beispiel die folgende Stelle extrahieren:
- Stellenbezeichnung: Techniker für Analog-Design
- Kompetenzen: Design, Testen, Schaltungsentwurf, Verilog, Phasenregelkreis, …
Wir trainieren das DNN, indem wir eine Kompetenz (z. B. Schaltungsentwurf) verbergen und das Modell auffordern, diese aus den anderen „Kontext“-Kompetenzen vorherzusagen: Design, Testen, Verilog, Phasenregelkreis, …
Das DNN wird anfangs Fehler bei der Vorhersage machen, aber der Trainingsprozess aktualisiert die Parameter des DNN, um diese Fehler zu reduzieren, indem der Standard-Backpropagation-Algorithmus verwendet wird. Dieser Prozess wird über viele Iterationen mit Millionen von Datensätzen wiederholt (unser typisches Setup verwendet etwa 45 Millionen Stellendatensätze), bis die DNN-Parameter zu einer Reihe von Werten konvergieren, welche die Vorhersagefehler ausreichend reduzieren.
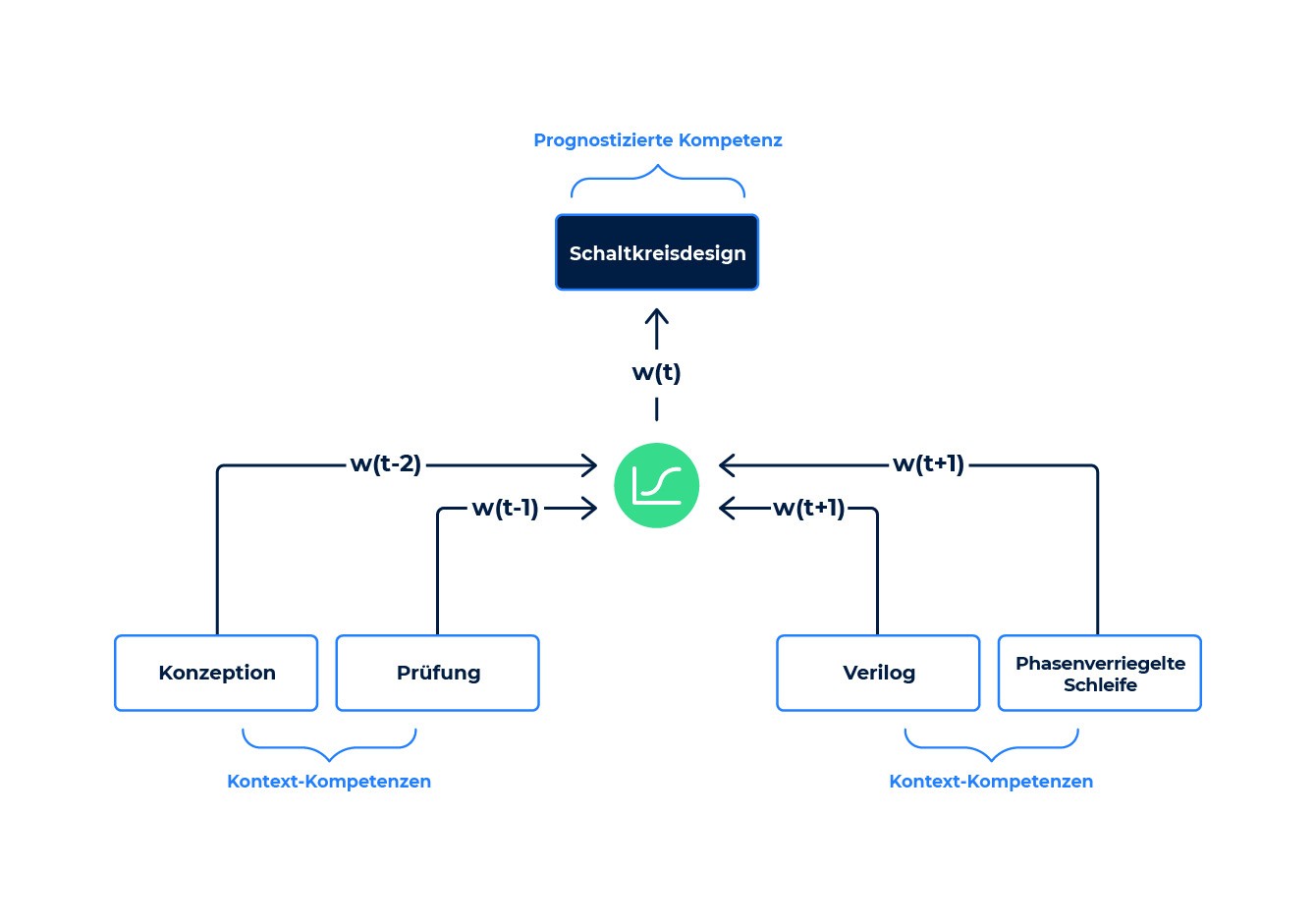
Beispiel für die Kompetenzeinbettung.
Das resultierende DNN kann nun jede Kompetenz in einem einzelnen Punkt im Einbettungsraum abbilden. Diese Abbildung hat eine wichtige Eigenschaft: Kompetenzen, die in einem ähnlichen Kontext vorkommen – und daher eine ähnliche Bedeutung haben – liegen im Einbettungsraum dicht beieinander. Das ist entscheidend, denn nun können wir den Grad der Ähnlichkeit in der Bedeutung der Kompetenzen quantitativ erfassen, indem wir den Abstand zwischen ihren Einbettungen im skill2vec-Raum messen. In unseren Einbettungen erhalten wir zum Beispiel ÄHNLICHKEIT(softwareentwicklung, java): 0.7136, während ÄHNLICHKEIT(softwareentwicklung, schreinern): 0,0706 um den Faktor zehn geringer ist.
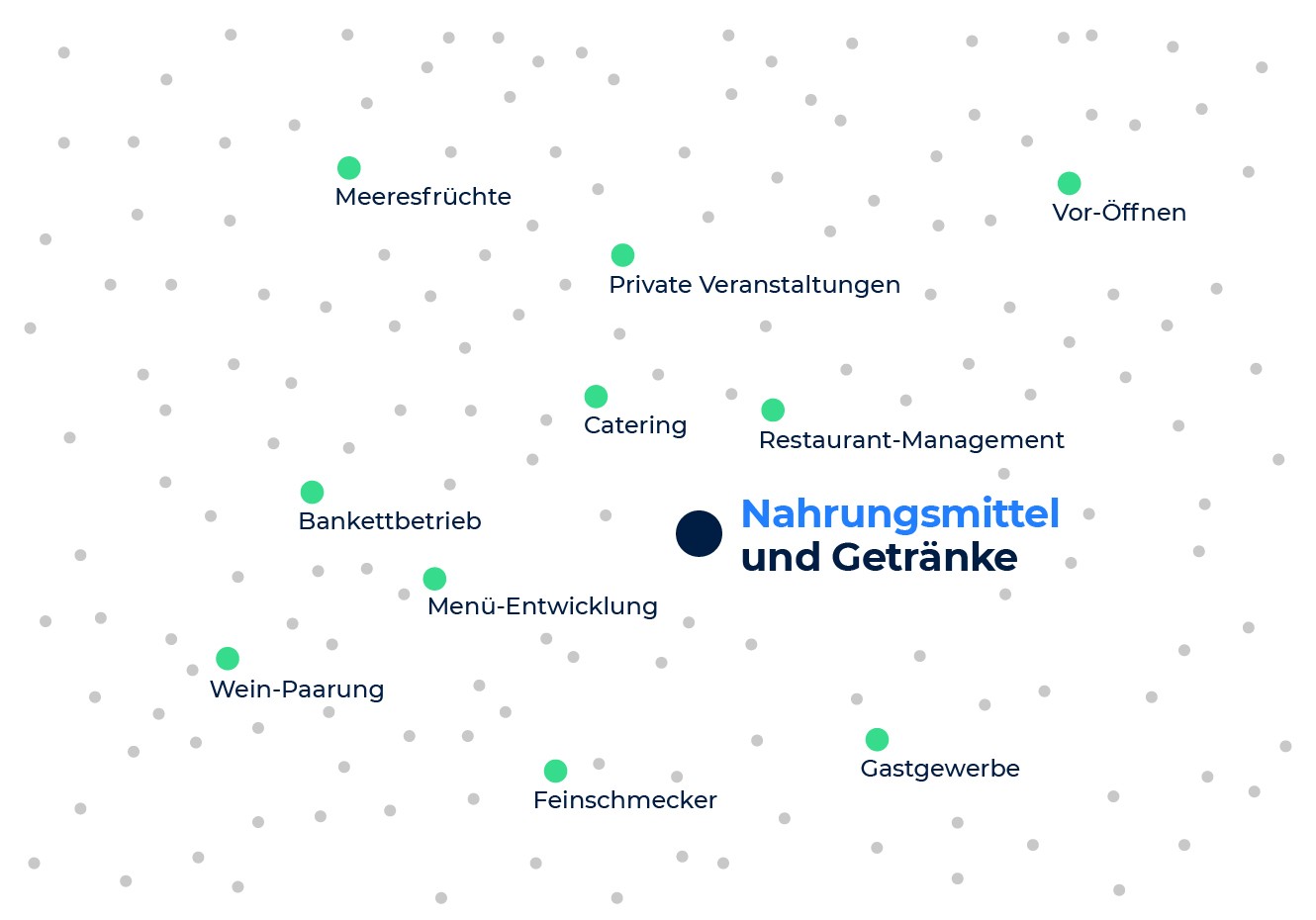
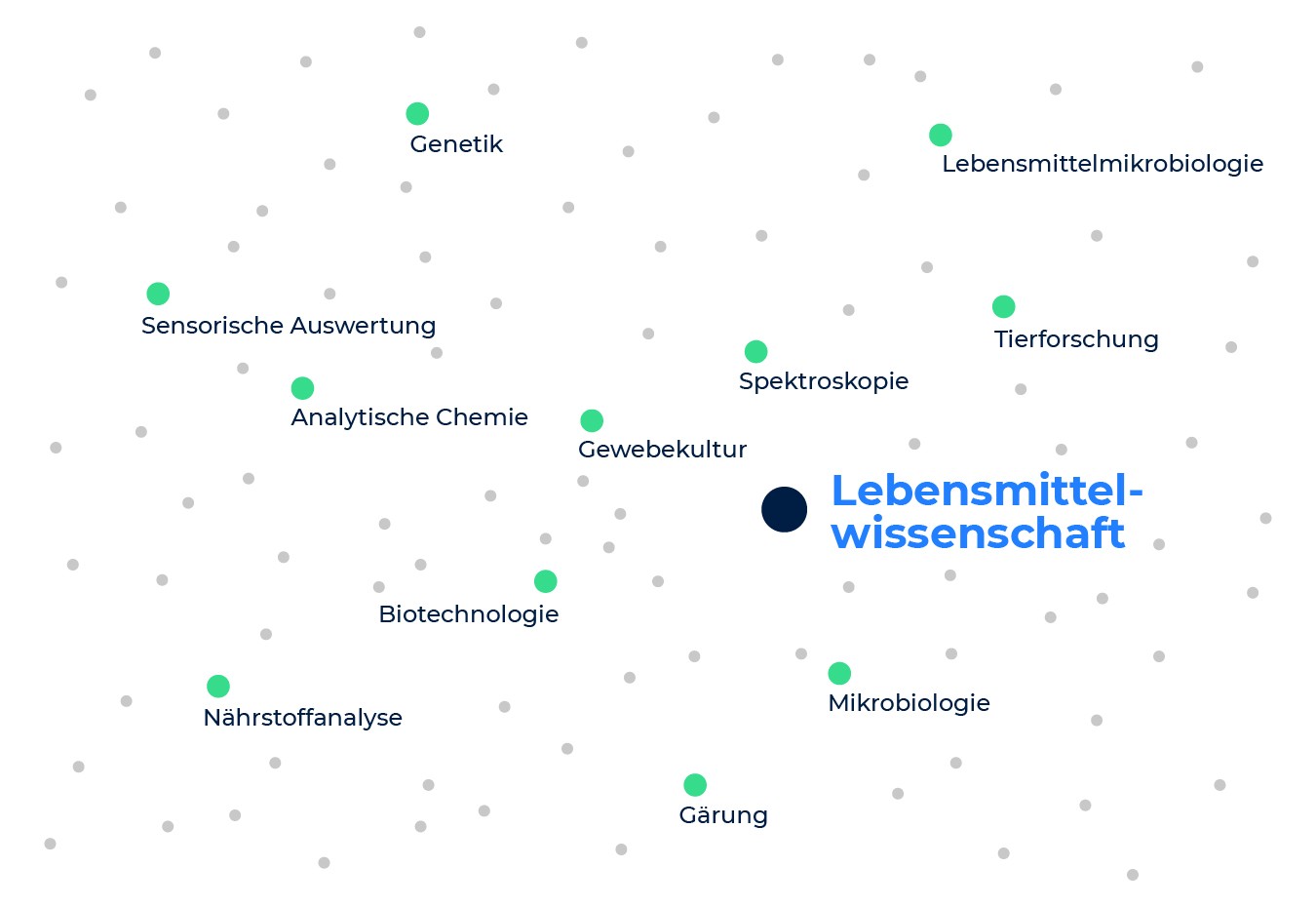
Schauen wir uns ein Beispiel an, um die Eigenschaften der Kompetenzeinbettung näher zu erläutern. Betrachten wir die beiden Kompetenzen: Lebensmittel und Catering und Lebensmittelwissenschaft. Wenn wir uns die Kompetenzen ansehen, die am engsten mit Lebensmittel und Catering verbunden sind, finden wir Restaurant-Management, Kochen, Catering, Menüentwicklung usw. Aber wenn wir uns die Kompetenzen ansehen, die der Lebensmittelwissenschaft am nächsten stehen, finden wir Molekularbiologie, analytische Chemie, Polymerase-Kettenreaktion und sensorische Bewertung.
Wir sehen, dass die beiden Kompetenzen sehr unterschiedliche Nachbarn haben, weil sie für zwei verschiedene Branchen relevant sind (die Lebensmitteldienstleistungsbranche vs. die Lebensmittelentwicklungs- und -herstellungsbranche), und jede impliziert einen anderen Satz von Kompetenzen. Und das, obwohl beide Kompetenzen das Wort Lebensmittel gemeinsam haben. Das zeigt, wie die Kompetenzeinbettung die Semantik der Kompetenzen erfasst und über Schlüsselwörter hinausgeht.
Die nächsten Nachbarn der Kompetenz „Lebensmittel und Getränke“
Die nächsten Nachbarn der Kompetenz „Lebensmittelwissenschaft“
Fazit
Die Kompetenzeinbettung ist der Grundpfeiler für viele unserer KI-gestützten Funktionen. Sie wird eingesetzt, um kompetenzbasierte Zuordnungen vorzunehmen oder um verwandte Kompetenzen vorzuschlagen. In der nächsten Folge erläutern wir, wie wir die Kompetenzeinbettung einsetzen, um ein Modell zur Messung der Ähnlichkeit zwischen Stellenbezeichnungen zu trainieren.
Wenn Ihnen dieser Einblick in das Zusammenspiel von KI und Machine Learning gefallen hat und Sie mehr erfahren möchten, können Sie sich gerne mit uns in Verbindung setzen. Sehen Sie sich auch unser Interview mit Fosway an, in dem wir unseren White-Box-Ansatz für KI in Avature etwas ausführlicher darlegen.

