Pour les organisations soucieuses de fournir aux candidats une expérience de qualité, les recommandations d’emploi intelligentes sont devenues une fonctionnalité incontournable des sites carrière afin de proposer aux visiteurs des offres d’emploi pertinentes. Cette même technologie procure également bien des avantages aux recruteurs, en leur permettant d’accélérer le processus d’identification des candidats qualifiés.
Des compétences au parcours scolaire, les systèmes dotés de fonctionnalités de matching (mise en correspondance) sont à même de prendre en compte une multitude de variables afin de déterminer la compatibilité entre les candidats et les postes à pourvoir. Toutefois, le parcours professionnel, et notamment la similarité des intitulés de poste, est l’un des facteurs essentiels.
En s’appuyant sur les fonctionnalités de sémantique des compétences, notre équipe de recherche en apprentissage automatique a développé une approche innovante destinée à appréhender la similarité sémantique entre les intitulés de poste, qui repose sur l’apprentissage non supervisé de la représentation.
Nous nous sommes entretenus avec notre expert maison en IA Rabih Zbib, Director of Natural Language Processing & Machine Learning, afin d’examiner les principaux aspects de ce travail, publiés dans l’ article de recherche « Learning Job Titles Similarity from Noisy Skill Labels » (Apprentissage des similarités entre les intitulés de poste à partir des étiquettes de compétences inexactes). De la méthode utilisée pour former le modèle à son fonctionnement, en passant par les avantages qu’il apporte à Avature et à ses clients, nous vous invitons à lire la suite pour en apprendre davantage sur le solide moteur d’IA qui alimente notre plate-forme.
En quoi cette approche est-elle novatrice ?
Nous voulions que notre modèle soit en mesure de comparer deux intitulés de poste et d’en déduire leur degré de similarité. Pour y parvenir, la solution classique consiste à développer un modèle supervisé entraîné sur un très vaste ensemble de données constitué de paires d’intitulés de poste, annotées manuellement par des personnes qui déterminent leur degré de similarité. Cependant, dans la mesure où l’annotation d’un ensemble de données assez conséquent constitue un processus lent et rigide, nos chercheurs en apprentissage automatique ont adopté une approche différente qui consiste à entraîner le modèle à l’aide de représentations sémantiques de l’intitulé de poste.
Nous reviendrons plus tard sur les détails techniques du modèle, mais avant tout, sachez que le modèle obtenu se distingue des autres approches disponibles sur le marché par deux caractéristiques clés :
- Il repose sur l’apprentissage non supervisé (une méthode résolument révolutionnaire dans le domaine de l’IA), le rendant par ailleurs plus généralisable, plus rentable et plus facile à étendre à un plus grand nombre de données, du fait qu’il ne fait pas intervenir d’annotations humaines.
- Ainsi, cette approche permet un développement et un déploiement plus rapides, ce qui offre à nos clients une valeur ajoutée substantielle tant sur le court que sur le long terme.
Pourquoi partir dans cette direction ?
Chez Avature, le moteur de l’innovation repose sur la création de valeur pour les clients en leur fournissant des outils performants qui améliorent leurs processus de gestion des talents. Il en va de même dans le cas présent. Nous avons choisi de privilégier cette approche en raison des nombreux avantages qu’elle procure à nos clients :
- Grâce à l’IA, les recruteurs de nos clients réalisent des gains de temps considérables et peuvent améliorer l’expérience de toutes les parties prenantes impliquées dans les processus liés aux talents. À mesure que nous introduisons de nouveaux modèles destinés à renforcer nos fonctionnalités d’IA multiplateformes et que nous les déployons rapidement, nous nous assurons également que nos clients puissent conserver ces avantages.
- Puisque le modèle opère au niveau sémantique, il permet de comparer les intitulés de poste de manière intelligente et pas exclusivement à partir d’une correspondance superficielle de mots-clés. De plus, le modèle est capable de généraliser, autrement dit de prédire des similarités notamment pour des intitulés de poste qui n’étaient pas inclus dans les données à partir desquelles le modèle a été entraîné. Il s’agit d’un atout majeur étant donné que, dans le monde du travail, de nouveaux intitulés de poste surgissent en permanence.
- La capacité à élaborer notre modèle d’apprentissage automatique sans annotation humaine nous permet de le mettre à jour plus rapidement et d’éviter qu’il ne devienne obsolète. Au fur et à mesure de l’évolution du marché du travail, notre faculté à procéder à des mises à jour périodiques de notre technologie d’IA de base permet de garantir à nos clients des résultats toujours pertinents, tout en évitant l’impact préjudiciable de la dérive du modèle.
- Les représentations sémantiques servant à l’apprentissage du modèle d’intitulés de poste ne dépendent pas de la langue. Grâce à cette approche, nous avons développé nos fonctionnalités en français, allemand, espagnol et italien, en plus de l’anglais, et notre feuille de route prévoit encore de nombreuses autres langues. Pour nos clients internationaux qui opèrent dans un grand nombre de pays, la possibilité d’exploiter de manière cohérente nos fonctionnalités d’IA dans plusieurs langues revêt une importance cruciale.
Comment fonctionne le modèle
Dans notre précédent article de blog sur la sémantique des compétences, nous avons décrit la manière dont les compétences sont modélisées en tant que vecteurs, ou points, dans un espace sémantique à haute dimension. Nous avons expliqué comment cet espace, élaboré à l’aide d’un modèle de réseau neuronal formé sur des données réelles, nous permettait de mesurer le degré de similarité entre les compétences en fonction de la distance entre leurs points respectifs dans cet espace. La sémantique des compétences est représentée par le biais de ces vecteurs (dénommés « embeddings » ou intégrations), dans ce que l’on appelle l’apprentissage par représentation.
Mais revenons-en aux intitulés de poste. L’équipe d’apprentissage machine d’Avature est parvenue à la conclusion qu’une représentation de l’intitulé de poste peut être obtenue à partir des représentations des compétences connexes. Dans cette optique, elle a extrait des compétences de millions de demandes d’emploi et des sections d’expérience professionnelle de CV anonymes, pour ensuite les associer aux intitulés de poste correspondants.
Ce travail a été effectué sur un très vaste ensemble de données, en combinant les compétences extraites de différents enregistrements de données mais correspondant au même intitulé de poste, ce qui a permis de déterminer le nombre de fois qu’une compétence a été associée au même intitulé de poste. Voici un aperçu du résultat :
Directeur de la communication : { « Relations publiques » : 135, « Réseaux sociaux “ : 128, « Campagnes » : 93, « Rédaction » : 55, « Stratégie » : 18, … }
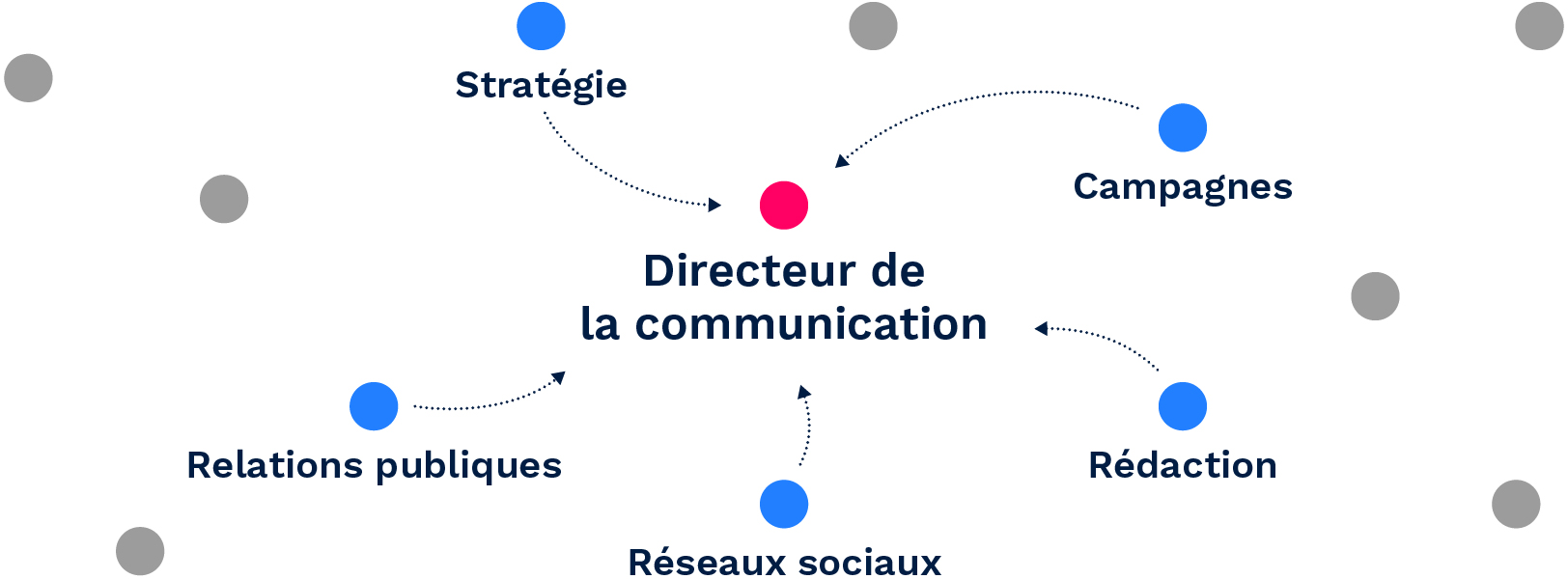
Figure 1. Obtention de la représentation d’un intitulé de poste à partir des compétences connexes.
Une représentation sémantique de l’intitulé de poste peut ensuite être obtenue en calculant la moyenne des vecteurs d’intégration pour l’ensemble des compétences connexes et au moyen de la pondération des chiffres afin de refléter l’importance de chaque compétence. Cette représentation pourrait être directement exploitée en vue de comparer les intitulés de poste.
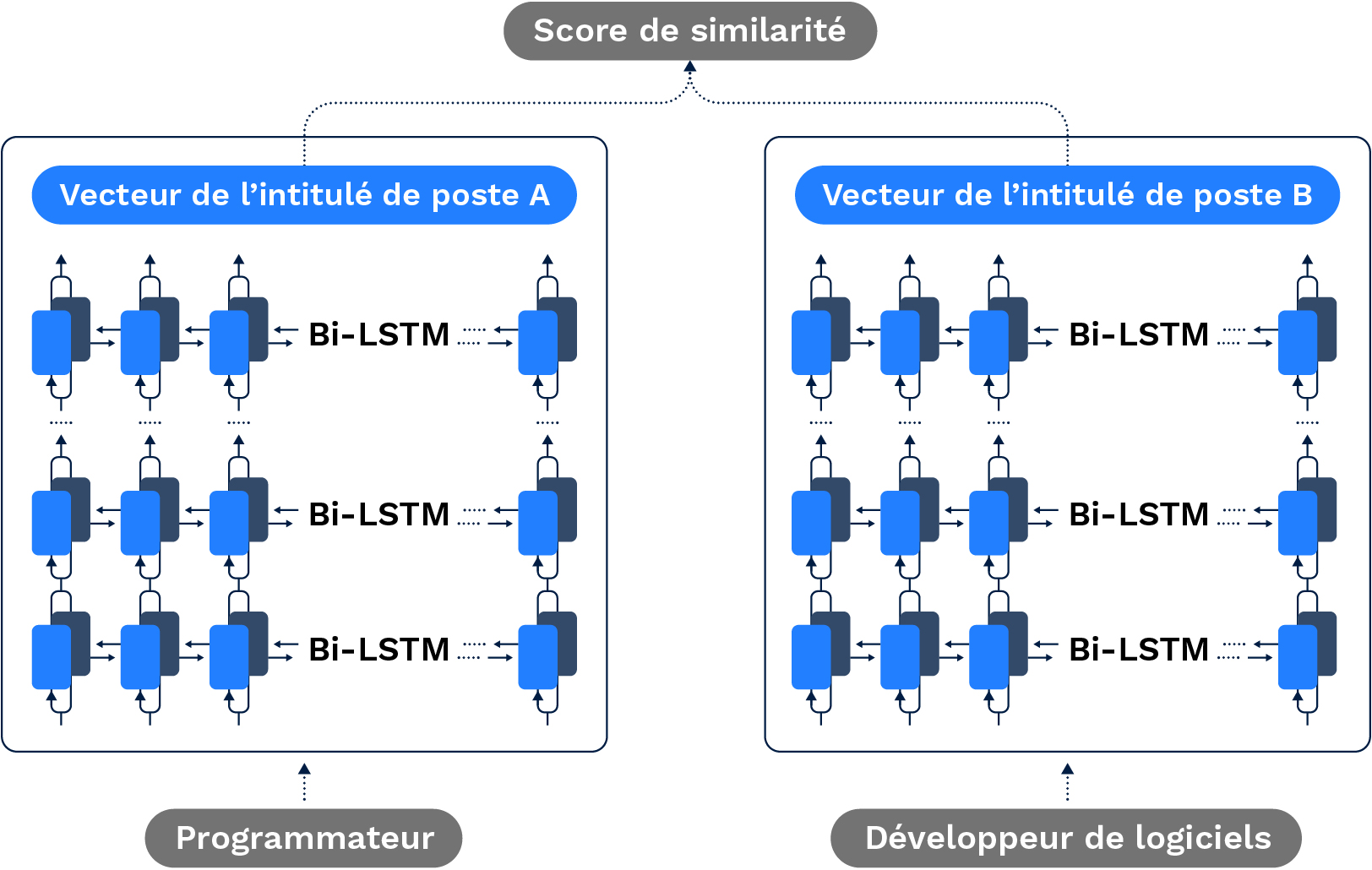
Figure 2. Exemple d’utilisation du modèle d’intitulés de poste. Les réseaux neuronaux récurrents génèrent un vecteur d’intégration pour chaque intitulé, afin d’en capturer la sémantique. Deux vecteurs sont ensuite comparés afin de déterminer la similarité entre leurs intégrations correspondantes.
Or, cette méthode se limiterait aux intitulés de poste rencontrés suffisamment de fois dans les données d’apprentissage. Pour que le modèle puisse généraliser, nous souhaitions aller encore plus loin. Nos chercheurs ont donc utilisé ces intitulés de poste en tant que représentations idéales (ou « objectifs » dans la terminologie de l’IA) et ont entraîné un réseau neuronal récurrent (ou RNN pour Recurrent Neural Network) à imiter cette représentation idéale.
Une fois entraîné, le RNN est capable alors de produire une telle représentation à partir de l’intitulé de poste. Cela comprend également les nouveaux intitulés de poste qui n’ont pas été rencontrés dans les données d’entraînement.
Une autre fonctionnalité essentielle de ce modèle réside dans le fait qu’il n’a pas besoin des compétences connexes pour produire l’intégration d’un intitulé de poste. Les compétences connexes servent uniquement à entraîner le modèle. L’équipe a donc atteint l’objectif qu’elle s’était fixé : un modèle capable de comparer deux intitulés de poste à partir de leur sémantique et qui, fait remarquable, a été formé au moyen de représentations non supervisées en lieu et place des annotations manuelles, lentes et coûteuses.
L’utilisation de la sémantique des compétences pour la représentation des intitulés de poste nous permet également de surmonter le principal obstacle au développement de l’intelligence artificielle, à savoir les données. Bien que les compétences soient exprimées dans une langue spécifique, par exemple l’anglais, en tant que concepts, celles-ci sont indépendantes de la langue. Les « relations publiques » sont toujours liées aux « réseaux sociaux », que ces compétences soient exprimées en anglais ou en allemand. Autrement dit, si nous voulons obtenir des données d’entraînement dans une nouvelle langue, il nous suffit de traduire les intitulés de poste de ces données en réutilisant la représentation sémantique en l’état. Cette propriété nous permet d’entraîner les modèles d’IA dans de nouvelles langues et d’offrir nos fonctionnalités d’IA pour ces langues en un temps record.
Développement pour la transparence et la flexibilité
Certains outils tels que ChatGPT ont popularisé l’IA à une échelle sans précédent. Pourtant, les conversations et les préoccupations entourant l’utilisation de cette technologie dans le recrutement ne datent pas d’hier. En fait, ces préoccupations ont conduit à un renforcement de la réglementation dans ce domaine. Par exemple, la ville de New York a adopté une loi qui obligera les employeurs à procéder à des audits relatifs aux préjugés des outils automatisés de prise de décision en matière d’emploi, notamment ceux qui ont recours à l’IA.
Conscients de l’importance pour nos clients de garantir des processus de recrutement de talents impartiaux et équitables, nous n’entraînons jamais nos modèles d’IA natifs à l’aide d’informations personnelles, telles que la couleur de peau, l’âge, le lieu de naissance et le sexe, entre autres. En outre, nous évitons tout préjugé implicite en ne recourant pas aux données historiques des décisions humaines dans le cadre de l’entraînement de nos modèles d’IA. Au contraire, notre approche repose sur la représentation, en modélisant la sémantique des attributs du profil du candidat, tels que les compétences ou l’intitulé de poste. Notre méthode d’apprentissage du modèle d’intitulés de poste s’inscrit dans cette philosophie.
Le principe de transparence va cependant au-delà de l’apprentissage du modèle. Le recours à un modèle fondé sur la représentation pour chaque type d’attribut permet de mettre en œuvre notre approche de l’IA en boîte blanche, en offrant aux utilisateurs d’Avature une visibilité et un contrôle absolus sur les rouages du système, de sorte à améliorer leur prise de décision sans pour autant la remplacer.
Nous nous efforçons de développer des modèles d’apprentissage automatique qui permettent de rationaliser les programmes de recrutement et de gestion des talents de nos clients, dans un premier temps avec la sémantique des compétences, et désormais avec les similarités entre les intitulés de poste. Notre objectif est avant tout de développer des technologies flexibles capables de relever les défis à venir.
Nous avons décidé il y a plusieurs années de développer nos algorithmes d’IA de manière native. Cela nous a permis de travailler en étroite collaboration avec nos clients de manière à innover en fonction de leur vision et de leurs besoins. Pour eux, cela se traduit par la possibilité de consulter librement les experts à l’origine des modèles, contrairement à ce que peuvent proposer les fournisseurs qui externalisent le développement de leurs algorithmes d’IA. Si vous souhaitez vous aussi vous entretenir avec nos spécialistes et en découvrir davantage sur nos modèles d’apprentissage automatique et nos fonctionnalités d’IA en général, contactez-nous.
Si vous désirez lire l’article dans son intégralité, veuillez cliquer sur le lien ci-dessous :
Rabih Zbib, Lucas Lacasa Alvarez, Federico Retyk, Rus Poves, Juan Aizpuru, Hermenegildo Fabregat, Vaidotas Simkus and Emilia Garcıa-Casademont, 2022, Learning Job Titles Similarity from Noisy Skill Labels, arXiv : 2207.00494 [cs.IR]


